JS正则表达式系列文章一三,《括号的作用》
前言
平时工作中,有时候在遇到某个问题的时,你可能想到用正则表达式能解决这个,可能这时候一个问题变成了两个问题,那这个正则表达式怎么写呢?所以我们今天来探讨下正则表达式的相关知识!
概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。 通过使用正则表达式,可以:
测试字符串内的模式。 例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 替换文本。 可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 基于模式匹配从字符串中提取子字符串。 可以查找文档内或输入域内特定的文本。
本文章为系列文章,往期系列文章:
今天我们继续来探究一下正则表达式括号的作用
括号的作用
不管哪门语言中都有括号。正则表达式也是一门语言,而括号的存在使这门语言更为强大。 对括号的使用是否得心应手,是衡量对正则的掌握水平的一个侧面标准。 括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。 引用某个分组,会有两种情形:在 JavaScript 里引用它,在正则表达式里引用它。
分组和分支结构
这二者是括号最直觉的作用,也是最原始的功能,强调括号内的正则是一个整体,即提供子表达式。
分组
我们知道 /a+/ 匹配连续出现的 "a",而要匹配连续出现的 "ab" 时,需要使用 /(ab)+/。 其中括号是提供分组功能,使量词 + 作用于 "ab" 这个整体。
可视化图:
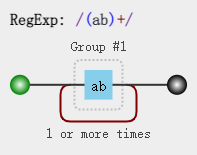
测试如下:
const regex = /(ab)+/g;
const string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
分支结构
而在多选分支结构 (p1|p2) 中,此处括号的作用也是不言而喻的,提供了分支表达式的所有可能。 比如,要匹配如下的字符串:
I love JavaScript I love Regular Expression 可以使用正则:
const regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true // => true
如果去掉正则中的括号,即:
/^I love JavaScript|Regular Expression$/
可视化图:
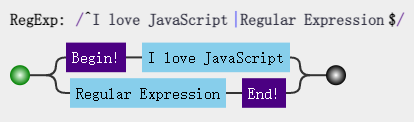
分组引用
这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。 而要使用它带来的好处,必须配合使用实现环境的 API。 以日期为例。假设格式是 yyyy-mm-dd 的,我们可以先写一个简单的正则:
/\d{4}-\d{2}-\d{2}/
可视化图:
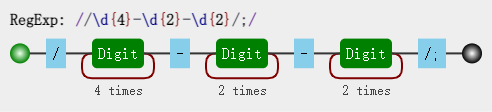
然后再修改成括号版的:
/(\d{4})-(\d{2})-(\d{2})/
可视化图:
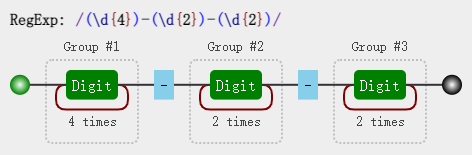
Group #1。 其实正则引擎也是这么做的,在匹配过程中,给每一个分组都开辟一个空间,用来存储每一个分组匹配到的 数据。 既然分组可以捕获数据,那么我们就可以使用它们。
提取数据
比如提取出年、月、日,可以这么做:
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
match返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的 内容,然后是匹配下标,最后是输入的文本。另外,正则表达式是否有修饰符g,match返回的数组格式是不一样的。
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
console.log( regex.exec(string) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
同时,也可以使用构造函数的全局属性
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
regex.test(string); // 正则操作即可
例如:
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1);
// "2017"
console.log(RegExp.$2);
// "06"
console.log(RegExp.$3);
// "12"
替换
比如,想把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy 怎么做?
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
const result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017
其中 replace 中的,第二个参数里用
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
const result = string.replace(regex, () => {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
也等价于:
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2017-06-12";
const result = string.replace(regex, (match, year, month, day) => {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
反向引用
除了使用相应 API 来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。 还是以日期为例。 比如要写一个正则支持匹配如下三种格式:
2016-06-12 2016/06/12 2016.06.12
最先可能想到的正则是:
/\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/
可视化图:
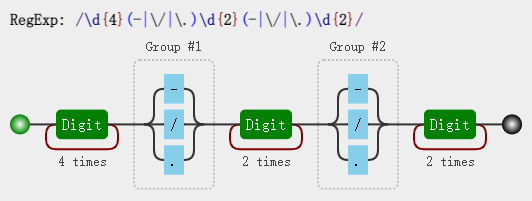
const regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
const string1 = "2017-06-12";
const string2 = "2017/06/12";
const string3 = "2017.06.12";
const string4 = "2016-06/12";
console.log( regex.test(string1) );
// true
console.log( regex.test(string2) );
// true
console.log( regex.test(string3) );
// true
console.log( regex.test(string4) );
// true
其中 / 和 . 需要转义。虽然匹配了要求的情况,但也匹配 "2016-06/12" 这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
/\d{4}(-|\/|\.)\d{2}\1\d{2}/
可视化图:
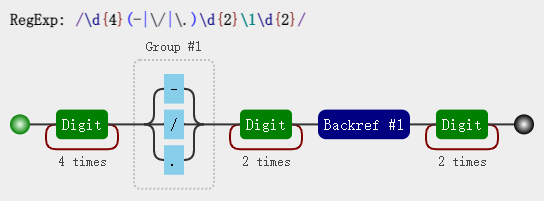
const regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
const string1 = "2017-06-12";
const string2 = "2017/06/12";
const string3 = "2017.06.12";
const string4 = "2016-06/12";
console.log( regex.test(string1) );
// true
console.log( regex.test(string2) );
// true
console.log( regex.test(string3) );
// true
console.log( regex.test(string4) );
// false
注意里面的 \1,表示的引用之前的那个分组 (-|\/|\.)。不管它匹配到什么(比如 -),\1 都匹配那个同 样的具体某个字符。
我们知道了 \1 的含义后,那么 \2 和 \3 的概念也就理解了,即分别指代第二个和第三个分组。 看到这里,此时,恐怕你会有几个问题。
括号嵌套怎么办?
以左括号(开括号)为准。比如:
/^((\d)(\d(\d)))\1\2\3\4$/
可视化图:
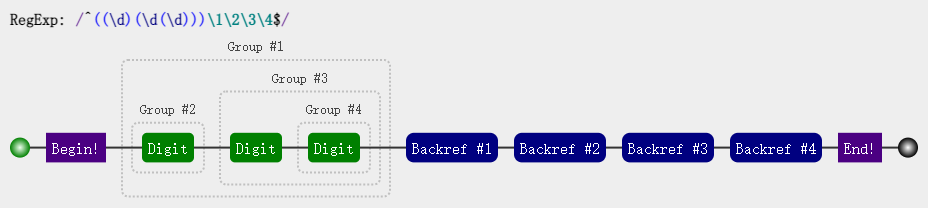
测试如下:
const regex = /^((\d)(\d(\d)))\1\2\3\4$/;
const string = "1231231233";
console.log( regex.test(string) );
// true
console.log( RegExp.$1 );
// 123
console.log( RegExp.$2 );
// 1
console.log( RegExp.$3 );
// 23
console.log( RegExp.$4 );
// 3
我们可以看看这个正则匹配模式:
第一个字符是数字,比如说 "1" 第二个字符是数字,比如说 "2" 第三个字符是数字,比如说 "3"
接下来的是 \1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是 "123"
接下来的是 \2,找到第2个开括号,对应的分组,匹配的内容是 "1"
接下来的是 \3,找到第3个开括号,对应的分组,匹配的内容是 "23"
最后的是 \4,找到第3个开括号,对应的分组,匹配的内容是 "3"
\10 表示什么呢?
另外一个疑问可能是,即 \10 是表示第 10 个分组,还是 \1 和 0 呢?
答案是前者,虽然一个正则里出现 \10 比较罕见。
/(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/
可视化图:

const regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/;
const string = "123456789# ######";
console.log( regex.test(string) );
// => true
如果真要匹配
\1和0的话,请使用(?:\1)0或者\1(?:0)。
引用不存在的分组会怎样?
因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配 反向引用的字符本身。例如 \2,就匹配 "\2"。注意 "\2" 表示对 "2" 进行了转义,
例如:
/\1\2\3\4\5\6\7\8\9/
测试如下:
const regex = /\1\2\3\4\5\6\7\8\9/;
console.log( regex.test("\1\2\3\4\5\6\7\8\9") );
// true
console.log( "\1\2\3\4\5\6\7\8\9".split("") );
// ['\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', '8', '9']
分组后面有量词会怎样?
分组后面有量词的话,分组最终捕获到的数据是最后一次的匹配。比如如下的测试案例:
const regex = /(\d)+/;
const string = "12345";
console.log( string.match(regex) );
// => ["12345", "5", index: 0, input: "12345"]
从上面看出,分组 (\d) 捕获的数据是 "5"。
同理对于反向引用,也是这样的。测试如下:
const regex = /(\d)+ \1/;
console.log( regex.test("12345 1") );
// => false
console.log( regex.test("12345 5") );
// => true
非捕获括号
之前文中出现的括号,都会捕获它们匹配到的数据,以便后续引用,因此也称它们是捕获型分组和捕获型分 支。 如果只想要括号最原始的功能,但不会引用它,即,既不在 API 里引用,也不在正则里反向引用。 此时可以使用非捕获括号 (?:p) 和 (?:p1|p2|p3),例如本章第一个例子可以修改为:
const regex = /(?:ab)+/g;
const string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
同理,第二例子可以修改为:
const regex = /^I love (?:JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true
// => true
相关案例
字符串 trim 方法模拟
trim 方法是去掉字符串的开头和结尾的空白符。有两种思路去做。
第一种,匹配到开头和结尾的空白符,然后替换成空字符。如:
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}
console.log( trim(" foobar ") );
// => "foobar"
第二种,匹配整个字符串,然后用引用来提取出相应的数据:
function trim (str) {
return str.replace(/^\s*(.*?)\s*$/g, "$1");
}
console.log( trim(" foobar ") );
// => "foobar"
这里使用了惰性匹配
*?,不然也会匹配最后一个空格之前的所有空格的,当然,前者效率高。
将每个单词的首字母转换为大写
function titleize (str) {
return str.toLowerCase().replace(/(?:^|\s)\w/g, function (c) {
return c.toUpperCase();
});
}
console.log(titleize('my name is epeli'));
// => "My Name Is Epeli"
思路是找到每个单词的首字母,当然这里不使用非捕获匹配也是可以的。
驼峰化
function camelize (str) {
return str.replace(/[-_\s]+(.)?/g, function (match, c) {
return c ? c.toUpperCase() : '';
});
} console.log( camelize('-moz-transform') );
// => "MozTransform"
中划线化
function dasherize (str) {
return str.replace(/([A-Z])/g, '-$1').replace(/[-_\s]+/g, '-').toLowerCas();
}
console.log( dasherize('MozTransform') );
// => "-moz-transform"
HTML 转义和反转义
// 将HTML特殊字符转换成等值的实体
function escapeHTML (str) {
const escapeChars = {
'<' : 'lt',
'>' : 'gt',
'"' : 'quot',
'&' : 'amp',
'\'' : '#39'
};
return str.replace(new RegExp('[' + Object.keys(escapeChars).join('') +']', 'g'),
function (match) {
return '&' + escapeChars[match] + ';';
});
}
console.log( escapeHTML('<div>Blah blah blah</div>') );
// => "<div>Blah blah blah</div>";
其中使用了用构造函数生成的正则,然后替换相应的格式就行了,这个跟括号没多大关系。 倒是它的逆过程,使用了括号,以便提供引用,也很简单,如下:
// 实体字符转换为等值的HTML。
function unescapeHTML (str) {
const htmlEntities = {
nbsp: ' ',
lt: '<',
gt: '>',
quot: '"',
amp: '&',
apos: '\''
};
return str.replace(/\&([^;]+);/g, function (match, key) {
if (key in htmlEntities) {
return htmlEntities[key];
}
return match;
});
}
console.log( unescapeHTML('<div>Blah blah blah</div>') );
// => "<div>Blah blah blah</div>"
通过 key 获取相应的分组引用,然后作为对象的键。
匹配成对标签
要求匹配:
<title>regular expression</title>
<p>laoyao bye bye</p>
但不匹配:
<title>wrong!</p>
匹配一个开标签,可以使用正则 <[^>]+>,
匹配一个闭标签,可以使用 <\/[^>]+>,
但是要求匹配成对标签,那就需要使用反向引用,如:
const regex = /<([^>]+)>[\d\D]*<\/\1>/;
const string1 = "<title>regular expression</title>";
const string2 = "<p>laoyao bye bye</p>";
const string3 = "<title>wrong!</p>";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // false
其中开标签 <[\^>]+> 改成 <([^>]+)>,使用括号的目的是为了后面使用反向引用, 而提供分组。闭标签使用了反向引用,<\/\1>。 另外[\d\D]的意思是,这个字符是数字或者不是数字,因此,也就是匹配任意字符的意思
结语
至此本章关于正则表达式括号的作用我们也了解了,接下来我们会继续探究正则表达式的回溯
本文章为系列文章,往期系列文章:
暂无评论,你来说两句?