JS正则表达式系列文章二,《位置匹配 》
前言
平时工作中,有时候在遇到某个问题的时,你可能想到用正则表达式能解决这个,可能这时候一个问题变成了两个问题,那这个正则表达式怎么写呢?所以我们今天来探讨下正则表达式的相关知识!
概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。 通过使用正则表达式,可以:
测试字符串内的模式。 例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 替换文本。 可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 基于模式匹配从字符串中提取子字符串。 可以查找文档内或输入域内特定的文本。
本文章为系列文章,上一篇我们讲到字符匹配,详情请看 JS正则表达式系列文章一 ,《字符匹配》,今天我们继续探究JS正则表达式
位置匹配
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话。 然而大部分人学习正则时,对于匹配位置的重视程度没有那么高。
什么是位置呢?
位置(锚)是相邻字符之间的位置。比如,下图中箭头所指的地方:
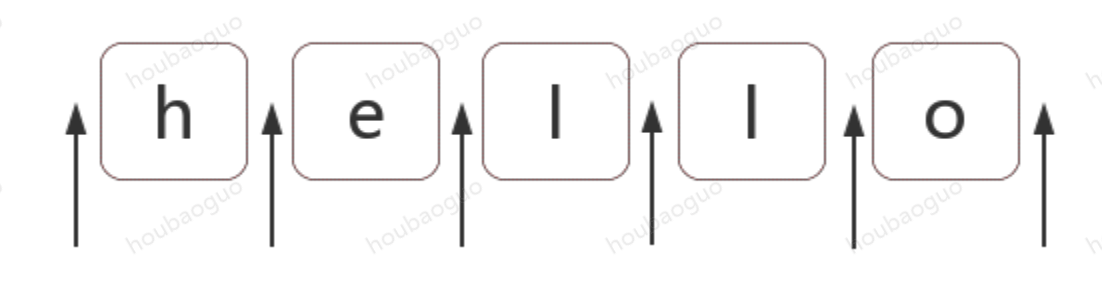
如何匹配位置呢?
在 ES5 中,共有 6 个锚: ^ 、 $ 、 \b 、 \B 、(?=p) 、(?!p)
解释说明:
| 模式 | 说明 |
|---|---|
| ^ | 匹配开头的位置,当正则有修饰符 m 时,表示匹配行开头位置。 |
| $ | 匹配结尾的位置,当正则有修饰符 m 时,表示匹配行结尾位置。 |
| \b | 匹配单词边界,即,\w 与 \W、^ 与 \w、\w 与 $ 之间的位置。 |
| \B | 匹配非单词边界,即,\w 与 \w、\W 与 \W、^ 与 \W,\W 与 $ 之间的位置。 |
| (?=abc) | 匹配 "abc" 前面的位置,即此位置后面匹配 "abc"。 |
| (?!abc) | 匹配非 "abc" 前面的位置,即此位置后面不匹配 "abc"。 |
可视化图:

^ 和 $
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用 "#" 替换(位置可以替换成字符的!):
const result = "hello".replace(/^|$/g, '#');
console.log(result);
// => "#hello#"
多行匹配模式(即有修饰符 m)时,二者是行的概念,这一点需要我们注意:
const result = "I\nlove\njavascript".replace(/^|$/gm, '#');
console.log(result);
/* #I# #love# #javascript# */
\b 和 \B
\b 是单词边界,具体就是 \w 与\W 之间的位置,也包括\w与^ 之间的位置,和\w 与 $ 之间的位置。 比如考察文件名 "[JS] Lesson_01.mp4" 中的 \b,如下:
const result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result);
// => "[#JS#] #Lesson_01#.#mp4#"
为什么是这样呢?这需要仔细看看。
首先,我们知道,\w 是字符组 [0-9a-zA-Z_] 的简写形式,即 \w 是字母数字或者下划线的中任何一个字 符。而 \W 是排除字符组 [^0-9a-zA-Z_] 的简写形式,即 \W 是 \w 以外的任何一个字符。
此时我们可以看看 "[#JS#] #Lesson_01#.#mp4#" 中的每一个井号 ,是怎么来的。
第 1 个,两边字符是 "["与"J",是\W与\w之间的位置。第 2 个,两边字符是 "S"与"]",也就是\w与\W之间的位置。第 3 个,两边字符是空格与 "L",也就是\W与\w之间的位置。第 4 个,两边字符是 "1"与".",也就是\w与\W之间的位置。第 5 个,两边字符是 "."与"m",也就是\W与\w之间的位置。第 6 个,位于结尾,前面的字符 "4"是\w,即\w与$之间的位置。
知道了\b 的概念后,那么\B 也就相对好理解了,\B就是 \b 的反面的意思,非单词边界。
例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。 具体说来就是\w 与\w、 \W与 \W、^与\W,\W 与 $ 之间的位置。
比如上面的例子,把所有 \B 替换成"#":
const result = "[JS] Lesson_01.mp4".replace(/\B/g, '#');
console.log(result);
// => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
(?=p) 和 (?!p)
(?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配p。
比如 (?=l),表示 "l" 字符前面的位置,例如:
const result = "hello".replace(/(?=l)/g, '#');
console.log(result);
// => "he#l#lo"
而 (?!p) 就是 (?=p) 的反面意思,比如:
const result = "hello".replace(/(?!l)/g, '#');
console.log(result);
// => "#h#ell#o#"
二者的学名分别是 positive lookahead 和 negative lookahead,中文翻译分别是正向先行断言和负向先行断言。
ES5 之后的版本,会支持 positive lookbehind 和 negative lookbehind。
具体是 (?<=p) 和 (?<!p)也有书上把这四个东西,翻译成环视,即看看右边和看看左边。 但一般书上,没有很好强调这四者是个位置。 比如 (?=p),一般都理解成:要求接下来的字符与p 匹配,但不能包括p匹配的那些字符,而在本人看来,(?=p) 就与 ^ 一样好理解,就是 p 前面的那个位置。
位置的特性
对于位置的理解,我们可以理解成空字符 ""。 比如 "hello" 字符串等价于如下的形式 :
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
也等价于:
"hello" == "" + "" + "hello"
因此,把 /^hello$/ 写成 /^^hello$$$/,是没有任何问题的:
const result = /^^hello$$$/.test("hello");
console.log(result);
// => true
甚至可以写成更复杂的:
const result = /(?=he)^^he(?=\w)llo$\b\b$/.test("hello");
console.log(result);
// => true
也就是说字符之间的位置,可以写成多个
把位置理解空字符,是对位置非常有效的理解方式。
案例分析
不匹配任何东西的正则
让你写个正则不匹配任何东西 ,easy,/.^/。
因为此正则要求只有一个字符,但该字符后面是开头,而这样的字符串是不存在的。
数字的千位分隔符表示法
比如把 "12345678",变成 "12,345,678"。 可见是需要把相应的位置替换成","。 思路是什么呢?
试着弄出最后一个逗号
使用 (?=\d{3}$) 就可以做到:
const result = "12345678".replace(/(?=\d{3}$)/g, ',')
console.log(result);
// => "12345,678"
其中,(?=\d{3}$) 匹配 \d{3}$ 前面的位置。而 \d{3}$ 匹配的是目标字符串最后那 3 位数字
弄出所有的逗号
因为逗号出现的位置,要求后面 3 个数字一组,也就是 \d{3} 至少出现一次。 此时可以使用量词 +:
const result = "12345678".replace(/(?=(\d{3})+$)/g, ',')
console.log(result);
// => "12,345,678"
匹配其余案例
写完正则后,要多验证几个案例,此时我们会发现问题:
const result = "123456789".replace(/(?=(\d{3})+$)/g, ',')
console.log(result);
// => ",123,456,789"
因为上面的正则,仅仅表示把从结尾向前数,一但是 3 的倍数,就把其前面的位置替换成逗号。因此才会出 现这个问题。 怎么解决呢?我们要求匹配的到这个位置不能是开头。 我们知道匹配开头可以使用 ^,但要求这个位置不是开头怎么办? easy,(?!^),你想到了吗?测试如下:
const regex = /(?!^)(?=(\d{3})+$)/g;
const result = "12345678".replace(regex, ',')
console.log(result);
// => "12,345,678"
result = "123456789".replace(regex, ',');
console.log(result);
// => "123,456,789"
支持其他形式
如果要把 "12345678 123456789" 替换成 "12,345,678 123,456,789"。 此时我们需要修改正则,把里面的开头 ^ 和结尾 $,修改成 \b:
const string = "12345678 123456789", regex = /(?!\b)(?=(\d{3})+\b)/g;
const result = string.replace(regex, ',')
console.log(result);
// => "12,345,678 123,456,789"
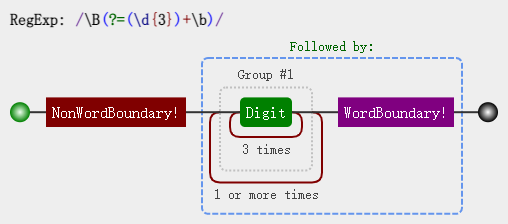
其中 (?!\b) 怎么理解呢? 要求当前是一个位置,但不是 \b 前面的位置,其实 (?!\b) 说的就是 \B。 因此最终正则变成了:/\B(?=(\d{3})+\b)/g。 可视化形式是:
格式化
千分符表示法一个常见的应用就是货币格式化。 比如把字符串 1888格式化成 $ 1888.00 ,
有了前面的铺垫,我们很容实现如下:
function format (num) {
return num.toFixed(2).replace(/\B(?=(\d{3})+\b)/g, ",").replace(/^/, "$$ ");
};
console.log(format(1888));
// => "$ 1,888.00"
$$ 表示美元符号
验证密码问题
密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符。 此题,如果写成多个正则来判断,比较容易。但要写成一个正则就比较困难。 那么,我们就来挑战一下。看看我们对位置的理解是否深刻。
简化
不考虑“但必须至少包括 2 种字符”这一条件。我们可以容易写出: /^[0-9A-Za-z]{6,12}$/
判断是否包含有某一种字符
假设,要求的必须包含数字,怎么办?此时我们可以使用 (?=.*[0-9]) 来做。 因此正则变成:
/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/
同时包含具体两种字符
比如同时包含数字和小写字母,可以用 (?=.*[0-9])(?=.*[a-z]) 来做。 因此正则变成:
/(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,12}$/
解答
我们可以把原题变成下列几种情况之一:
同时包含数字和小写字母 同时包含数字和大写字母 同时包含小写字母和大写字母 同时包含数字、小写字母和大写字母
以上的 4 种情况是或的关系(实际上,可以不用第 4 条)
最终答案是:
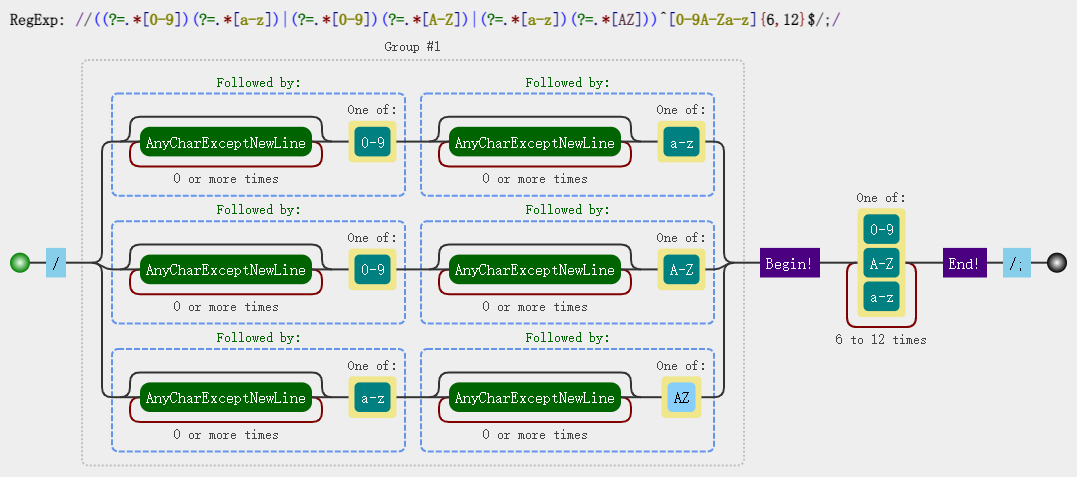
const regex = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[AZ]))^[0-9A-Za-z]{6,12}$/;
console.log( regex.test("1234567") );
// false 全是数字
console.log( regex.test("abcdef") );
// false 全是小写字母
console.log( regex.test("ABCDEFGH") );
// false 全是大写字母
console.log( regex.test("ab23C") );
// false 不足6位
console.log( regex.test("ABCDEF234") );
// true 大写字母和数字
console.log( regex.test("abcdEF234") );
// true 三者都有
可视化图:
解惑
上面的正则看起来比较复杂,只要理解了第二步,其余就全部理解了。
/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/对于这个正则,我们只需要弄明白 (?=.*[0-9])^ 即可, 分开来看就是 (?=.*[0-9]) 和^,表示开头前面还有个位置(当然也是开头,即同一个位置,想想之前的空字符类比)。 (?=.*[0-9]) 表示该位置后面的字符匹配 .*[0-9],即,有任何多个任意字符,后面再跟个数字。 翻译成大白话,就是接下来的字符,必须包含个数字。
另外一种解法
“至少包含两种字符”的意思就是说,不能全部都是数字,也不能全部都是小写字母,也不能全部都是大写 字母。 那么要求“不能全部都是数字”,怎么做呢? (?!p) 出马! 对应的正则是:
/(?!^[0-9]{6,12}$)^[0-9A-Za-z]{6,12}$/
三种“都不能”呢?
最终答案是:
const regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
console.log( regex.test("1234567") );
// false 全是数字
console.log( regex.test("abcdef") );
// false 全是小写字母
console.log( regex.test("ABCDEFGH") );
// false 全是大写字母
console.log( regex.test("ab23C") );
// false 不足6位
console.log( regex.test("ABCDEF234") );
// true 大写字母和数字
console.log( regex.test("abcdEF234") );
// true 三者都有
可视化图:

结语
至此我们把关于正则JS表达式的位置匹配了解了,其实还蛮有趣的对吧,下章将会继续介绍正则表达式括号的作用
暂无评论,你来说两句?